第 5 章 – 軟體品質
軟體最怕的是有 bug,但是要能夠寫出沒有 bug 的軟體,並不那麼容易,這就是本章的第一個重點。
除了盡力去除 bug 之外,程式的品質,像是《可讀性、容錯性、擴充性》等等,也都是本章所討論的範圍。
可讀性
程式不只是給使用者用的,還要具有可讀性,這樣才會容易維護修改。
舉例而言,下列這個程式碼就不太好讀!
function chunk(array=[], n) {
const clist = []
for (let i=0; i < array.length; i+=n) {
clist.push( array.slice(i, i + n))
}
return clist
}
module.exports = chunk
當然,如果排版成以下這樣,那就更難讀了。
function chunk(array=[], n) { const clist = []
for ( let i=0;
i < array.length; i+=n) {
clist.push( array.slice(i, i + n))
}
return clist
} module.exports = chunk
為了讓程式好讀,而且不容易出錯,有許多語法檢查工具,還有自動排版工具被發展出來。
像是《jslint, eslint, StandardJS》就是 JavaScript 的語法檢查工具 (其他語言也有類似的 lint 工具,例如 C 語言的 lint 就是這類工具的老祖先)。
語法檢查除了讓程式好看之外,其實也可以提高程式品質,降低 bug 數量,舉例而言,以下的程式碼排版看起來不錯,但是如果我們用 StandardJS 檢查,會發現不少問題。
if (age = -1) {
console.log('error: age < 0')
}
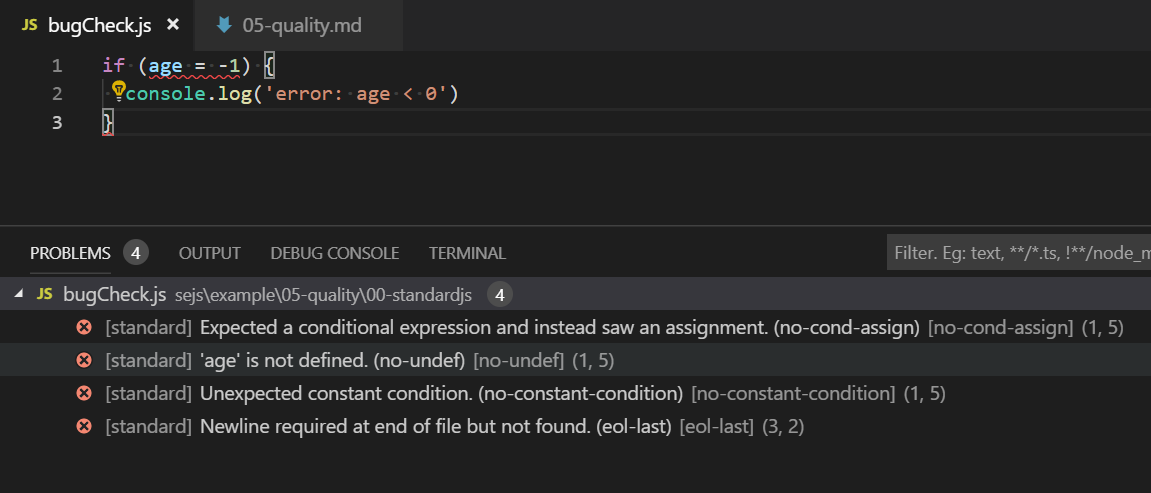
這些問題包含
- if 裡面用指定 (age = -1) 是錯的,標準寫法應該是 (age === -1) 才對
- age 未定義
於是我們根據這些指示,就可以發現潛在的錯誤,進而修正程式,解決方法如下。
var age
if (age === -1) {
console.log('error: age < 0')
}
同樣的,語法檢查工具也可以檢查出下列程式的語法問題,提醒你可能發生的錯誤。
for (counter = 0; counter < 10; counter ++) {
if (counter = 3) continue
console.log(counter)
}
Eslint 這類工具是可以訂製的,您可以自行決定那些問題要警告,那些問題不檢查。
但是 StandardJS 則是不可訂製的,其實 StandardJS 是建築在 Eslint 之上,只是規定了一組標準語法,要求大家嚴格遵循而已,以下是 StandardJS 的官網。
然後你可以在 Visual Studio Code 中安裝 StandardJs 的語法檢查器,就能在編輯的當下看到程式的問題。
但是每次都要手動排版,其實是非常累人的事情,有時候會真的很想關掉警告,因為這樣會使得你無法專注在撰寫程式上,而是一直在調整程式的排版格式。
還好,有一種稱為 prettier 的功能,可以幫你作自動排版,例如以下的 Visual Studio Code 插件,就可以幫你自動調整為 StandardJS 的格式。
您只要安裝之後,在程式上按下快捷鍵《Shift-Alt-F》,程式立刻就會調整成 StandardJS 的標準格式。
這樣應該非常好用了,但是好還要更好!
有時如果很多檔案都要調整格式,我們還一個檔案一個檔案去打開後再調,也會浪費不少時間,此時我們只要安裝 prettier-standard 這個套件,套件網址如下:
然後用 prettier-standard ’lib/**/*.js’ 這樣的指令,一次就可以把全部程式調整好。
PS D:\course\sejs\project\ccclodash> npm i prettier-standard -g
PS D:\course\sejs\project\ccclodash> prettier-standard 'lib/**/*.js'
success formatting 3 files with prettier-standard
1 file was unchanged
問題是,這樣還得下個指令,還是不夠自動化,因此我們可以使用 husky 與 lint-stage 這兩個套件,就能在 git 上傳之前,自動地將程式排好後才上傳。 (懶還要更懶,沒有最懶、只有更懶 ….)
{
"scripts":{
"precommit": "lint-staged"
},
"lint-staged": {
"linters": {
"src/**/*.js": [
"prettier-standard",
"git add"
]
}
}
}
當然,也有些人是刻意搞怪,想要寫出很難看懂又可以執行的程式,甚至還舉辦比賽,以下的《國際C語言混亂程式碼大賽》就是一個世界盃的難懂代碼比賽,您或許會想挑戰看看!
程式錯誤 (bug)
但是不管你的程式格式有多漂亮,有多好讀,語法檢查器仍然沒辦法查出所有的錯誤,特別是語意或邏輯上的錯誤。
舉例而言,以下的 chunk 程式,隱含的一個錯誤,光是用肉眼看會很難看出來。
function chunk (array = [], n) {
const clist = []
for (let i = 0; i <= array.length; i += n) {
clist.push(array.slice(i, i + n))
}
return clist
}
module.exports = chunk
當我們用 mocha 寫測試程式去測時,就會發現這類錯誤。
PS D:\course\sejs\project\ccclodash> mocha test/chunkTest.js
chunk
1) _.chunk(['a', 'b', 'c', 'd'], 2) equalTo [ [ 'a', 'b' ], [ 'c', 'd' ] ]
√ _.chunk(['a', 'b', 'c', 'd'], 3) equalTo [ [ 'a', 'b', 'c' ], [ 'd' ] ]
√ _.chunk(['a', 'b', 'c', 'd'], 3) notEqualTo [ [ 'a', 'b'], ['c' , 'd' ] ]
2 passing (64ms)
1 failing
1) chunk
_.chunk(['a', 'b', 'c', 'd'], 2) equalTo [ [ 'a', 'b' ], [ 'c', 'd' ] ]:
AssertionError [ERR_ASSERTION]: Input A expected to strictly deep-equal input B:
+ expected - actual ... Lines skipped
[
[
...
'd'
- ],
- []
+ ]
]
+ expected - actual
[
"c"
"d"
]
- []
]
at Context.<anonymous> (test\chunkTest.js:7:12)
由於錯誤非常細微,用肉眼很難發現,其實就只是差一個等號,把 i < array.length 打成了 i <= array.length,這時只要把等號去掉,再測一次就修正好這個 bug 了!
預防 bug
醫學上常說《預防勝於治療》,對於程式而言,也經常是如此,程式設計者必須要設計各種《防呆措施》,以便能偵測錯誤使用的情況。
這些《防呆措施》大致可以分為下列數類:
- 使用 if 處理錯誤使用的情況。
- 使用 throw,在錯誤使用時丟出例外。
- 使用 assert,在錯誤使用時丟出例外並停止。
- 使用 try … catch {} 捕捉並處理例外的情況。
第一種錯誤處理方式比較傳統,像是 node.js 裡讀檔錯誤時,我們常常會用 if (err) … 的方式處理
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err;
console.log(data);
});
上述程式立刻示範了 throw 的作用,不過 throw 也不只限用於輸出入失敗,像是參數類型或範圍錯誤也可以用 throw 處理,以下是一個範例。
function chunk (array = [], n = 1) {
if (!(Number.isInteger(n) && n >= 0)) throw Error('chunk: n should be a positive integer')
if (!Array.isArray(array)) throw Error('chunk: first argument should be an array')
const clist = []
for (let i = 0; i <= array.length; i += n) {
clist.push(array.slice(i, i + n))
}
return clist
}
當然我們也可以用 assert 來限制參數的型態與範圍,像是這樣:
function chunk (array = [], n = 1) {
assert.ok(Number.isInteger(n) && n >= 0, 'chunk: n should be a positive integer')
assert.ok(Array.isArray(array), 'chunk: first argument should be an array')
const clist = []
for (let i = 0; i <= array.length; i += n) {
clist.push(array.slice(i, i + n))
}
return clist
}
由於 JavaScript 是個《弱型態語言》 (變數沒有明確型態),因此這種檢查的程式碼會很繁瑣,對於《強型態語言》來說,就不需要檢查變數型態,只需要檢查《變數範圍》就行了。
有不少人企圖去改造 JavaScript,幫 JavaScript 加上型態,像是微軟的 TypeScript 就是如此。
Facebook 也出了一個幫 JavaScript 加上型態的工具,稱為 flow.js。如果你為程式加上型態,那麼 flow.js 會自動檢查型態不相容的問題。如果你沒加型態,那麼就不會檢查。
假如你不用 flow.js 與 TypeScript,但是又覺得用 Number.isInteger 這樣的語法有點太冗長,可以考慮使用 is.js 這個函式庫,會讓檢查程式精簡不少。
上述的幾種錯誤處理,幾乎都著重在丟出例外,或者是避開意外情況,屬於《預防錯誤的方法》。
但是最後一種的 try … catch 錯誤處理機制,則是在《捕捉例外》,算是一種《治療的手段》。
舉例而言、以下的 try .. catch 錯誤處理,就是在治療當輸出入失敗時,程式應該怎麼解決,是應該《終止程式,關閉已開啟資源,還是應該再丟出例外》,這就得視目前程式的角色而定了。
// ...
let fd;
try {
fd = fs.openSync(process.argv[2]), 'a');
fs.appendFileSync(fd, appendData, 'utf8');
} catch (err) {
/* Handle the error */
} finally {
if (fd !== undefined)
fs.closeSync(fd);
}
浮點數的 bug
電腦的浮點數,由於精確度是有限的,因此只是一種《近似值》,而不是真實值,也因此常會造成某些 bug,需要特別小心。
舉例而言,以下的案例都是浮點數的天性,並不是《意外情況》…
$ node
> 0.1+0.2
0.30000000000000004
> (0.1+0.2)===0.3
false
所以數學上對的事情,在浮點數表達法之下很可能會變成錯的,歷史上許多著名的 bug 災難,常常都是浮點數造成的。
進階閱讀: 使用浮點數最最基本的觀念
– 這篇文章把浮點數的問題講得很清楚,並且在最後舉了很多歷史上浮點數 bug 所造成的災難,非常值得一讀!
語言陷阱
大部分的語言都有一些缺陷,JavaScript 和 C/C++ 語言的缺陷則是特別多,但奇怪的是這些語言又特別有用,因此在使用的時候就更應該特別小心,先瞭解語言的缺陷並避開它們。
以下的執行結果,或許會讓你感到意外,寫程式的時候要特別避開這些陷阱。
$ node
> 3 == "3"
true
> '' == 0
true
> 0 == ''
true
> 1 == ''
false
> null == undefined
true
> null === undefined
false
> ' \r\n ' == 0
true
> {} == {}
false
> {} === {}
false
> function f() {
... return
... {
..... a:3
..... }
... }
undefined
> f()
undefined
> typeof NaN
'number'
> typeof []
'object'
> typeof null
'object'
> typeof undefined
'undefined'
> parseInt('2.57')
2
> parseInt('2 is a prime number')
2
> parseInt('015')
15
> parseInt('015', 8)
13
> for( var i in [ 21, 22, 23 ] ) { console.log( i ); };
0
1
2
undefined
> var a = [ 30, 31, 32]
undefined
> a.name = 3
3
> a
[ 30, 31, 32, name: 3 ]
> a.length = 5
5
> a
[ 30, 31, 32, <2 empty items>, name: 3 ]
> var a = [ 32, 14, 11, 112, 17 ]
undefined
> a.sort()
[ 11, 112, 14, 17, 32 ]
> typeof null
'object'
> typeof undefined2
'undefined'
> typeof []
'object'
> typeof {}
'object'
> typeof "abc"
'string'
> typeof true
'boolean'
> typeof function(){}
'function'
> typeof class {}
'function'
> NaN === Nan
ReferenceError: Nan is not defined
> NaN === NaN
false
> NaN !== NaN
true
> isNaN(NaN)
true
> isNaN('abc')
true
> isNaN('0')
false
> var i=1
undefined
> if (i=2) console.log('i!=1')
i!=1
看了以上這些案例之後,我應該會小心地避開這些陷阱,實在是太可怕了!
模組化
良好的模組化是提高程式品質的好方法,在設計函數模組時,記得遵循一些原則。像是:
- KISS 原則: 能簡單就不要複雜的
- KISS: Keep It Simple and Stupid
- SRP 原則: 單一的函數只做一個功能。
- SRP : Single Responsibility Principle
- 提高內聚力,降低附著力。
- 變數命名應有意義,不要只是為了求短。
- 盡量少用全域變數。
- 程式風格要盡可能統一。
- 恰當的註解,並保持註解與程式的一致性。
- 避免使用奇技淫巧。
另外、物件導向也有一些設計準則可以依循
- 慎用繼承,可改用組合 (Composition) 代替
- LSP 原則: 子型態必須可以被父型態取代
- LSP : Liskove Substitution Principle
- 正例: Shape <= Circle, Rectangle
- 反例: Rectangle <= Square
- PLK 最小知識原則: 人命令狗,但不要命令狗的腿
- PLK: Principle of Least Knowledge
- 狗的腿由狗自己去命令操控
- 好萊塢原則: 低階元件不要呼叫高階元件
- Hollywood Principle
- 而是像驅動程式一樣,先註冊後由高階元件呼叫低階元件。
- OCP 開放封閉原則: 模組必須容易被改變,但卻不需要大改
- OCP: Open Closed Principle
- 使用依賴性注射、多型之類的技巧達成
- DIP 依賴反向原則:高階模組不應依賴低階模組,兩者必須依賴抽象層運作。
- DIP : Dependency Inversion Principle
- IoC 控制反轉原則: 使用依賴注射 DI 完成。
- IoC: Inversion of Control
- DI : Dependence Injection (以下列出三種 DI)
- 建構子注入 (Constructor Injection)
- 設定屬性注入 (Setter Injection)
- 介面參數注入 (Interface Injection)
- SOI 介面分離原則: 採用 interface 避免多重繼承
- SOI: Separation of Interface
- 迪米特法則: 盡量不要與無關的物件產生關係。
- 對被呼叫函式傳回的物件,不該再呼叫該物件內的方法
- 像是 ctxt.getOptions().getScratchDir().getAbsolutePath() 就違反迪米特法則。
- 但是 jQuery 那類傳回自身的鏈式語法,並沒有違反迪米特法則。
使用說明
對於一般的軟體,如果不是一用就能上手的那種,那麼就應該撰寫使用說明。
但是對於給程式呼叫的函式庫而言,那麼函數的 API 應該要是透過《API 文件產生器》,從程式中自動抽取建構出來的才對。
在 node.js 的開發工具裏,有個稱為 jsdoc 的文件產生器,可以從程式中抽取並產生《API 說明文件》,以下我用自己仿照 lodash 寫的 ccclodash 作為範例。
定義 chunk 函數
/**
* Creates an array of elements split into groups the length of `size`.
* If `array` can't be split evenly, the final chunk will be the remaining
* elements.
*
* @memberof _
* @since 0.1.0
* @category Array
* @param {Array} array The array to process.
* @param {number} [size=1] The length of each chunk
* @returns {Array} Returns the new array of chunks.
* @example
*
* _.chunk(['a', 'b', 'c', 'd'], 2)
* // => [['a', 'b'], ['c', 'd']]
*
* _.chunk(['a', 'b', 'c', 'd'], 3)
* // => [['a', 'b', 'c'], ['d']]
*/
function chunk(array = [], n) {
const clist = [];
for (let i = 0; i < array.length; i += n) {
clist.push(array.slice(i, i + n));
}
return clist;
}
module.exports = chunk;
定義主物件的 namespace
/** @namespace _ */
module.exports = {
chunk: require('./lib/chunk'),
compact: require('./lib/compact'),
concat: require('./lib/concat'),
flattenDeep: require('./lib/flattenDeep')
}
當我們撰寫這樣格式的說明後,就可以在安裝好 jsdoc 與樣板 docdash 後,用下列指令產生 API 文件:
$ jsdoc index.js lib -r -d docs -t node_modules/docdash
我們也可以將該指令寫在 package.json 裏,使用 npm run docs 的指令來產生文件
"scripts": {
"docs": "jsdoc index.js lib -r -d docs -t node_modules/docdash"
},
呈現結果 – https://se107a.github.io/ccclodash/docs/index.html
您可以看到在 github 裏,比較常被使用的 API 函式庫,己乎都有很詳細的說明文件,通常就是這麼來的,這對使用該函式庫的程式開發者是很有幫助的!
結語
在本章中我們學習了下列主題
- 用 eslint, StandardJs 等工具檢查語法
- 用 prettier 工具對程式進行自動排版
- Bug 的避免、預防與治療方法
- if, throw, assert, try … catch
- 模組化的一些原則
- 如何用 jsdoc 抽取並產生 API 文件
練習
基本參考:https://github.com/cccbook/sejs/tree/master/example/05-quality 進階參考: https://github.com/se107a/ccclodash
練習 1 – 正確排版
針對你的 lodash 專案
- 請用 StandardJS 檢查你的程式並調整到沒有任何語法問題。
- 請用 prettier-standard 對你的程式進行自動排版。
練習 2 – Bug 處理
針對你的 lodash 專案
- 請找出你程式中的還有甚麼 bug
- 請用 throw/assert 預防這些 bug,提早警報!
- 請寫一個程式使用 try .. catch 捕捉檔案開啟失敗的錯誤。
- 請查出 strict.js 的錯誤之所在並修正之!
練習 3 – 產生說明
請修改你的 lodash 專案,為你的專案加上 api 文件
- 為你的專案加上 jsdoc 格式的說明
- 然後用 jsdoc 自動產生該專案的說明
- https://github.com/se107a/ccclodash/blob/master/package.json
- jsdoc index.js lib -r -d docs -t node_modules/docdash
- 記得安裝 jsdoc 與 docdash (另外你使用到的套件 mocha, chai, … ) 也要裝好
- 最後再次用 npm publish 出版你的套件。
完整參考: https://github.com/se107a/ccclodash
練習 4 – 效能分析
- 請對你的 lodash 專案進行 Profiling 效能地圖分析!
現在、您應該學會如何提高程式品質的一些方法了,下一章我們將從最高層的巨觀角度,由上而下的觀察軟體專案開發的方法,像是《軟體開發模式、